


Web scraping is the technique of extracting data from a specific website or web page. This has wide applications in:
- Research and publication purposes
- Competitor and market studies
- Creating data for machine learning models
The extracted data can be stored in any format be it a csv, txt, json, API etc so that it can easily be consumed by the user.
How does web scraping work?
In web scraping, you raise an HTTP request to the server of the website that contains the data you are looking for. Then we programmatically download the HTML code behind the web page. This (along with CSS and Javascript) is the source code that gets rendered by your web browser into the nice-looking web pages. Once you’ve extracted the HTML, then you can extract the data you want in the format desired.
A more efficient way to do this is, instead of reading the entire HTML, you can identify the parts of the page which contain the data and read only those parts.
Why is web scrapping required? Why not manually copy the data from the website and paste into a word doc or notepad?
There are couple of reasons:
- In most of websites, due to security frameworks, you can’t simply copy-paste the content on the website.
- Additionally, if you have to extract the data from multiple pages, doing it manually will take a lot of time.
For example, you have to extract the specifications of all the cars available on a car information website. There will be thousands of pages on that website. If you tend to extract this information manually, you will have to click on all the pages and it will take days or months of your time. On top of that, you will have to filter out the content as well, as you might have also copied information which is not relevant to you.
To enhance this process and increase the efficiency of teams, web scrapping is used.
It might sound very simple, but it’s not that simple. The reason is that various websites are designed in different ways, be it in terms of the language they are built on, or the server they are hosted on, or security frameworks installed on the website, etc. And perhaps the custom code that the programmers use might make it difficult to standardize data extraction. Using libraries like scrapy helps a lot.
Hence, a clear understanding of HTML DOM structure is required in order to scrap the data.
The most popular libraries for web scrapping are Beautiful Soup and Scrapy.
Let’s understand in a bit more detail.
Beautiful Soup
Beautiful Soup is a very popular and widely used python library which parses the unstructued and unwanted data and helps to structue and format the messy web data by fixing bad HTML and present to us in an easily-traversible XML structures. It works based on a tree like structure where it forms a tree of information where you can extract the relevant information in form of a dictionary.
It formats the outgoing data into UTF-8, and formats the incoming data into Unicode.
It’s easy-to-use syntax and familiarity with python is the reason behind huge popularity amongst early stage coders. If you know python, you will be able to learn and use beautiful soup very quickly.
One very important to note is that, it is a python library. It doesn’t work as an stand alone, independent tool for scrapping.

Install BeautifulSoup
It’s very easy to install beautiful soup and get started with it. You can install it from PyPi using pip install command (PyPi stands for Python Package Index, it is a repository of library for the Python).
Install Beautiful Soup in Windows and MacOS
pip install BeautifulSoup4
If you are using Linux (Debian) you can install it with following command
# (for Python 2)
`$ apt-get install python-bs4`
# (for Python 3)
`$ apt-get install python3-bs4`
When you install it, be it in Windows, MacOS or Linux, it gets stored as BS4.
You can import BeautifulSoup from BS4 library using following command
from bs4 import BeautifulSoup
It has a very clear, well written documentation here. Have a look if you wish to have a more detailed example of scraping with beautifulsoup.
Scrapy
Scrapy is an open-source and collaborative web scraping tool used to extract the desired data from websites or webpages. It’s very popular amongst developers for perfroming complex web scrapping because of it’s structured way of approaching web crawling, fast speed (works well on multithreading) and compatability with other frameworks.
Scrapy is opinionated tool unlike other web scrapping tools, i.e. it works with a standard set of rules and conventions, which allow you to solve the usual web scraping problems in an elegant way.
It is an API based framwork which can be used to build tailored web spiders. It comes with built-in functionality to extracting data from HTML or XML sources using CSS expression and XPath expressions.
So, it’s a complete framework in itself which can work independently and can be used for other purposes as well apart from data extraction. Ex. It can be used for automated monitoring or testing on a website.
Install Scrapy
Similar to Beautiful Soup, It’s also very easy to install. You can install it from PyPi using pip install command.
Let’s see how to install Scrapy in Windows and MacOS
pip install scrapy
If you are using Debian or Linux you need to install few dependencies of Scrapy and then you can install it with the pip command itself.
Use following commands to install all the dependencies.
$ sudo apt-get install python3 python3-dev python3-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
It have a very light documentation unlike Beautiful Soup. You can read more here
Creating a Scrapy Project
Once Scrapy is installed, we can create a new Scrapy project using the startproject command. Open a terminal window and navigate to the directory where you want to create your project. Then, run the following command:
!pip install scrapy
First step is to start a project by creating the necessary folder structure. After installing scrapy, you will be able to execute the following command in terminal / anaconda prompt. If you are using jupyter lab, you can execute the same from inside the notebook cell by adding a ! at the beginning of the statement.
scrapy startproject reddit_scraper
Output
New Scrapy project 'reddit_scraper', using template directory 'C:\Users\Akash\anaconda3\envs\mlenv2\Lib\site-packages\scrapy\templates\project', created in:
C:\MLPlus\02_Blogs\reddit_scraper
You can start your first spider with:
cd reddit_scraper
scrapy genspider example example.com
This creates a new project directory called ‘reddit_scraper’ which contains various pre-created python files that you will edit for the scrapy project.
The structure of the project that gets created is as follows:
reddit_scraper/
scrapy.cfg # deploy configuration file
reddit_scraper/ # project's Python module, import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
This has created a new directory called reddit_scraper that contains the basic structure of a Scrapy project.
Creating a Spider
In Scrapy, a spider is a Python class that defines how to crawl a website and extract data from it.
We can create a new spider using the genspider command. In this example, we’ll create a spider to crawl the Reddit website and extract information about the top posts in a specific subreddit.
Run the following command from terminal to create a new spider:
cd reddit_scraper
scrapy genspider reddit_spider reddit.com/r/learnpython
This will create a new spider called ‘reddit_spider’ in the spiders directory of your Scrapy project. It will also pre-populate the spider with some boilerplate code.
Defining the Spider
Now that we have created a spider, we need to define how it will crawl the website and extract data from it. Open the reddit_spider.py file in your text editor and modify the start_urls list to contain the URL of the subreddit you want to scrape:
import scrapy
class RedditSpider(scrapy.Spider):
name = 'reddit_spider'
start_urls = ['https://www.reddit.com/r/learnpython/']
Next, we need to define how the spider will parse the response from the website. In this example, we’ll extract the title and URL of each post in the subreddit.
class RedditSpider(scrapy.Spider):
name = 'reddit_spider'
start_urls = ['https://www.reddit.com/r/learnpython/']
def parse(self, response):
for post in response.css('div.Post'):
yield {
'title': post.css('h3._eYtD2XCVieq6emjKBH3m::text').get(),
'url': post.css('a._2_tDEnGMLxpM6uOa2kaDB3::attr(href)').get(),
}
In the parse method, we use the CSS selector div.Post to select each post on the page. Then, for each post, we use CSS selectors to extract the title and URL. We use the yield keyword to return a dictionary with the extracted data.
Running the Spider
Now that we have defined the spider, we can run it using the scrapy crawl command:
scrapy crawl reddit_spider -o posts.json
Make sure you are cd’d to the projects folder when you run the above command. It starts the crawl and gives back a number of outputs.
This will run the spider and save the extracted data to a file called posts.json. You can change the filename and format of the output by changing the -o option.
Beautiful Soup vs Scrapy: What’s the difference?
Fundamental difference is that, BeautifulSoup is more of a HTML parser that can be used to extract specific portions of a webpage. Whereas, Scrapy is a more of a framework designed to crawl and extract information from whole websites and is capable of doing that elegantly in a structured way.
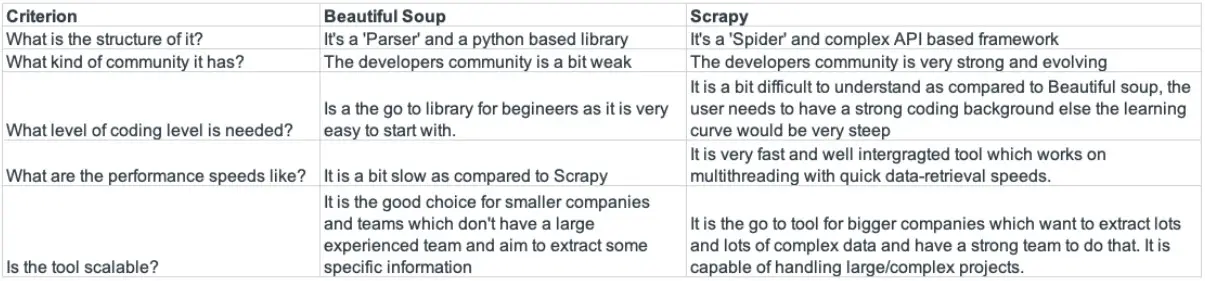
Conclusion
Both the tools have their different use case and team strengths.
Scrapy should be the preferred choice for teams and companies which are working on complex projects and their data requirements keeps changing over time. Additionally they should have a strong team with good coding experience.
On the other hand, Beautiful Soup should be the preferred choice for small teams and companies whose data requirements are more or less constand and are not very time bound. Even with a beginners team, they will be able to do it complete it fairly quickly.

